



新浪科技讯 北京时间6月15日消息,据国外媒体报道,在近期的一项新研究中,美国麻省理工学院的科学家开发了一种标记和检索DNA数据文件的技术,这或许能让DNA数据存储成为可能。
此时此刻,地球上大约有10万亿吉字节(GB)的数据量,而每一天,人类制造出来的电子邮件、照片、社交媒体动态和其他数字文件加起来,又有250万吉字节的数据。这些数据中的大部分都存储在名为“艾字节(exabyte,简称EB)数据中心”的巨大设施中(1EB相当于10亿GB),其规模可能有几个足球场那么大,建造和维护成本约为10亿美元。
许多科学家认为,解决天量数据存储问题的另一种办法在于包含我们遗传信息的生物大分子:脱氧核糖核酸(DNA)。从地球生命诞生至今,DNA已经进化到可以以极高的密度存储大量信息,理论上一个装满DNA的咖啡杯就可以存储世界上所有的数据。
我们需要新的解决方案,来存储世界正不断积累的大量数据,尤其是档案数据,DNA的密度甚至是闪存的1000倍。另一个有趣的特性是,DNA聚合物一旦制造出来,它就不会再消耗任何能量。你可以把数据写入DNA,然后永久存储起来。
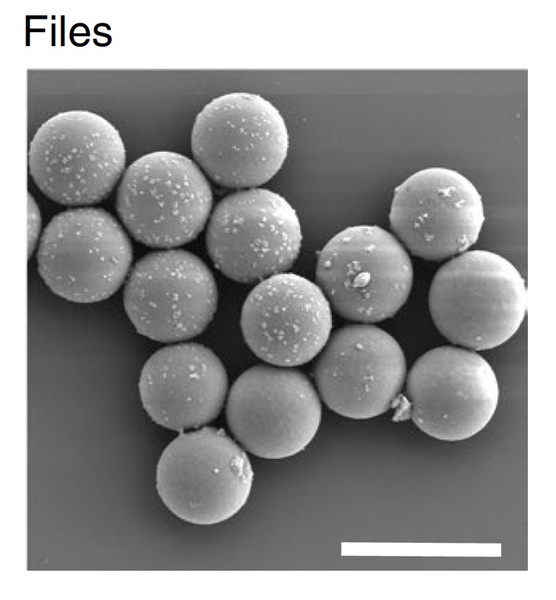
科学家已经证明,图像和文本可以编码为DNA,但我们还需要一种从许多DNA片段混合物中挑选出所需文件的简单方法。在新研究中,科学家展示了一种方法,能将每个数据文件封装到一个6微米的二氧化硅球形“胶囊”中,并使用DNA短序列作为标签,以显示其文件内容。
利用这种方法,研究人员从包含20张图像的DNA文件中准确提取出了以DNA序列形式存储的单个图像。考虑到可以用到的标签数量,这种方法最多能扩展到10^20个文件。
稳定的存储介质
数字存储系统将文本、照片和其他类型的信息都编码为一系列的0和1,同样的信息也可以用构成遗传密码的4种核苷酸(A、T、G和C,即腺嘌呤、胸腺嘧啶、鸟嘌呤和胞嘧啶)编码在DNA中。例如,G和C可以代表0,而A和T代表1。
作为存储介质,DNA还具有其他几个特点。首先,它非常稳定,而且合成和测序都相当容易(但目前还十分昂贵)。其次,它具有非常高的存储密度——1个核苷酸相当于2个比特,大约为1立方纳米。因此,以DNA形式存储的数据完全可以放在我们的手掌中。
这种存储数据的新方法面临着诸多障碍,首先就是合成如此大量DNA需要耗费的成本。目前,写入1拍字节(100万GB)的数据需要花费1万亿美元。为了与磁带(通常用于存储档案数据)竞争,估计DNA合成的成本需要降低约6个数量级,这一目标可能会在10年或20年内实现,就像过去几十年来闪存存储信息的成本大幅下降一样。
除了成本之外,使用DNA存储数据的另一个主要瓶颈是,我们很难从所有文件中挑选出想要的文件。
假设写入DNA的技术已经很先进,可以实现在DNA中写入1艾字节或1泽字节(zettabyte,简称ZB,1ZB=1000EB)数据的成本效益,会发生什么?你会有一大堆的DNA,也就是无数的文件、图像或电影和其他东西,但你需要在其中找到想要的某一张图片或某一部电影,这就像大海捞针。
目前,DNA文件通常使用PCR(聚合酶链式反应)方法来检索。每个DNA数据文件都包含一个与特定PCR引物结合的序列。为了读取某个特定的文件,需要将该引物添加到样品中,找到并放大所想要的序列。然而,这种方法的一个缺点是,引物与目标序列以外的DNA序列之间可能存在串扰,导致不必要的文件输出。此外,PCR的检索过程需要用到酶,最终会消耗库中的大部分DNA,这有点像在干草堆里找一根针,因为其他所有DNA都没有被放大,因此基本上它们都被扔掉了。
解决DNA文件检索难题
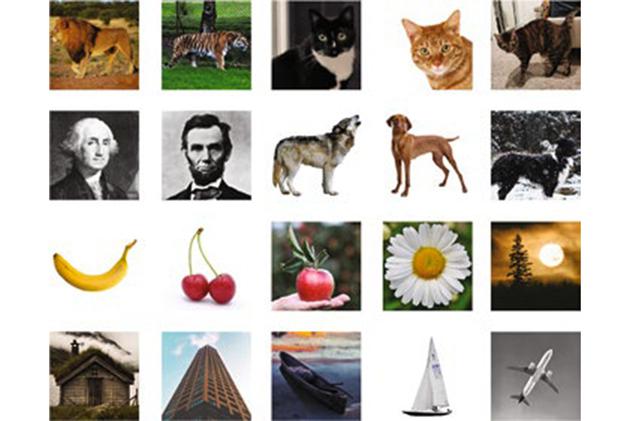
麻省理工学院的研究小组开发了一种新的检索技术,希望取代PCR方法。他们将每个DNA文件封装到一个微小的二氧化硅胶囊中,每个胶囊都贴上了由单链DNA组成的“条形码”,与文件内容相对应。为了证明这种方法的成本效益,研究人员将20个不同的图像编码到大约长度为3000个核苷酸的DNA片段中,这大致相当于100个字节(他们的研究还显示,这些胶囊可以容纳高达1GB的DNA文件)。
研究中的每个文件都有相应的条形码标签,如“猫”或“飞机”等。当研究人员想要提取一个特定的图像时,他们会取出一个DNA样本,加入与目标标签相对应的引物。例如,老虎的图像对应的标签是“猫”“橘色”和“野生”,而家猫的图像对应“猫”“橘色”和“家养”。
这些引物用荧光或磁性颗粒标记,便于从样本中提取并识别匹配片段。通过这种方法,研究人员可以将需要的文件移出来,剩下的DNA则完整地放回去,继续存储数据。他们的检索过程允许布尔逻辑语句,如“总统和18世纪”会生成“乔治·华盛顿”的结果,这很类似谷歌的图像检索。
在目前的概念验证阶段,搜索速度是每秒1000字节(1KB)。文件系统的搜索速度是由每个胶囊的数据量大小决定的,而目前限制数据量大小的因素就是在DNA上写入100兆字节(MB)数据所需的高昂成本,以及可以并行使用的分类器的数量。如果DNA合成变得足够便宜,就能够用这种方法将每个文件存储的数据量最大化。
研究人员所使用的条形码——单链DNA序列——取自哈佛医学院遗传学和医学教授史蒂芬·埃利奇开发的序列库,其中包含了10万个序列。如果给每个文件贴上两个这样的标签,就可以唯一地标记100亿(10^10)个不同的文件;如果每个文件上有4个标签,就可以唯一地标记10^20个文件。
在DNA中写入、复制、读取,以及用DNA进行低能耗的档案数据存储方面,我们取得了快速进步,但这也使得从巨大的数据库(10^21字节,泽字节规模)中精确检索数据文件变得极为困难,这项新研究引人注目的地方在于,它使用一个完全独立的DNA外层解决了这个问题,扩展了DNA的不同属性(杂交而非测序),而且使用的是现有的仪器和化学试剂。
科学家设想这种DNA封装技术可以用于存储“冷”数据,即保存在档案中但不经常访问的数据。目前,研究实验室已经成立了一家名为Cache DNA的初创公司,正在开发DNA的长期存储技术,既可以用于长期的DNA数据存储,也能用于短期的临床和其他现有的DNA样品存储。
虽然我们可能还需要一段时间才能将DNA作为数据存储介质,但目前在Covid-19检测、人类基因组测序和其他基因组学领域中,对于DNA和RNA样品的低成本和大规模存储的解决方案都有很紧迫的需求。